City of Engagement, with a total population of 50,000, is a small city located at Country of Nowhere. The city serves as a service centre of an agriculture region surrounding the city. The main agriculture of the region is fruit farms and vineyards. The local council of the city is in the process of preparing the Local Plan 2023. A sample survey of 1000 representative residents had been conducted to collect data related to their household demographic and spending patterns, among other things. The city aims to use the data to assist with their major community revitalization efforts, including how to allocate a very large city renewal grant they have recently received.
2. Task
Reveal demographic and financial characteristics of the city of Engagement, using appropriate static and interactive statistical graphics methods.
Provide user-friendly and interactive solutions for data exploration using ggplot2.
3. Data
Dataset 1 - Participants.csv
Contains information about the residents of City of Engagement that have agreed to participate in this study.
Participants.csv Dataset
Column Name
Data Type
Description
participantId
integer
unique ID assigned to each participant
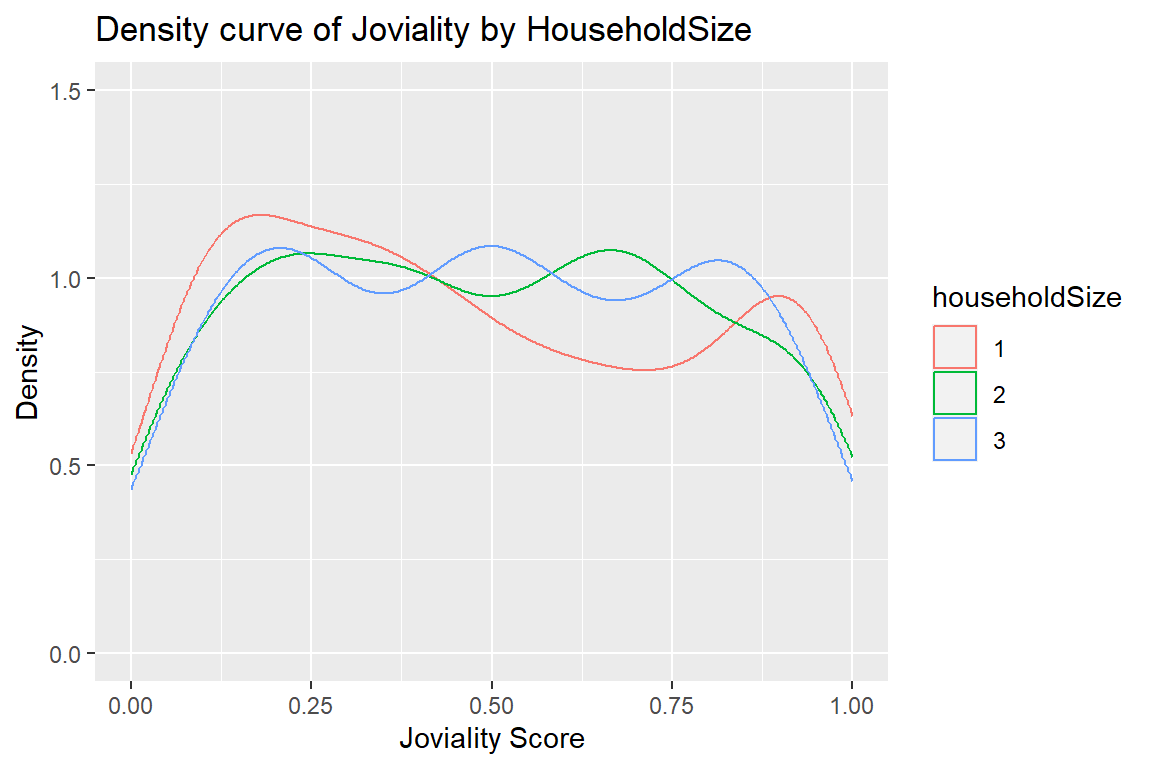
householdSize
integer
the number of people in the participant’s household
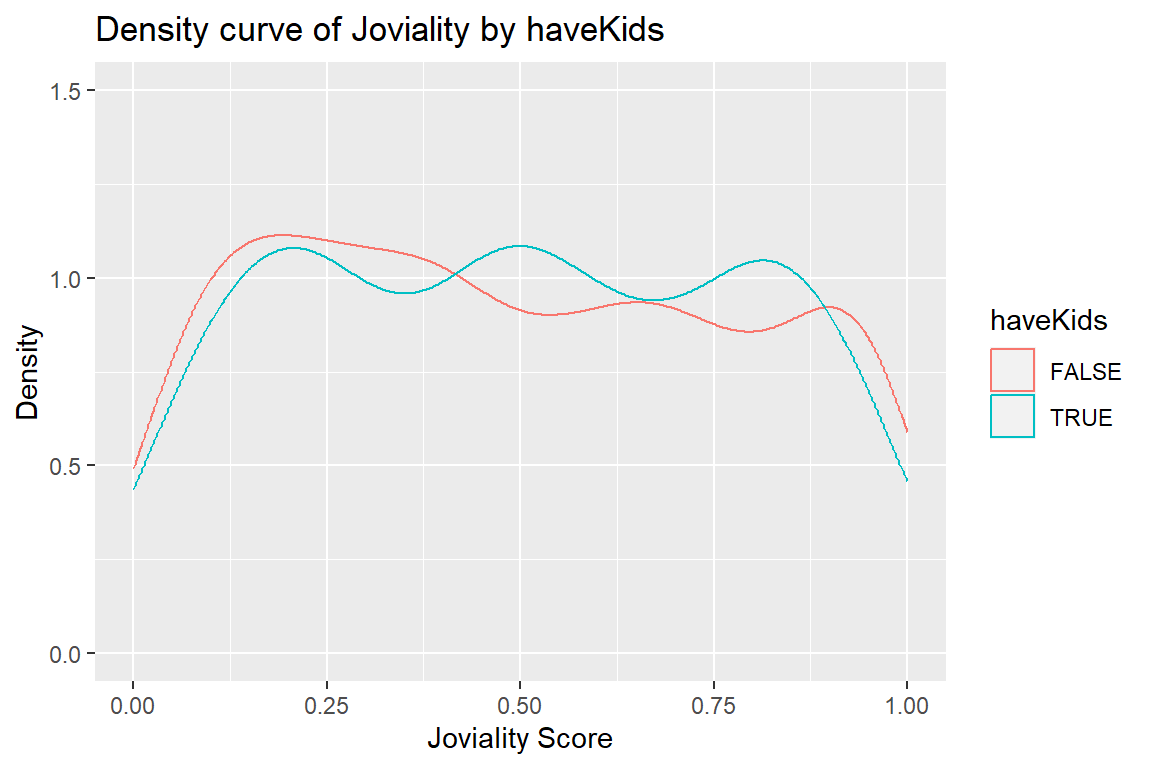
haveKids
boolean
whether there are children living in the participant’s household
age
integer
participant’s age (in years) at the start of the study
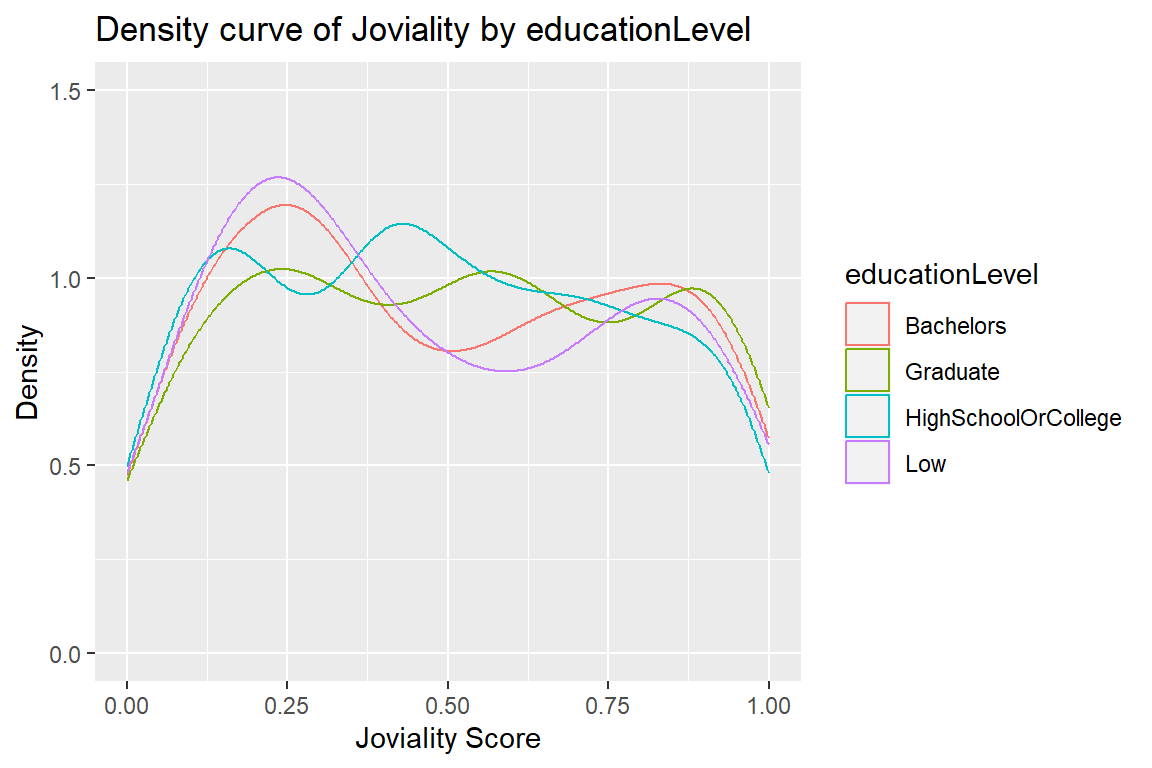
educationLevel
string factor
the participant’s education level, one of: {“Low”, “HighSchoolOrCollege”, “Bachelors”, “Graduate”}
interestGroup
char
a char representing the participant’s stated primary interest group, one of {“A”, “B”, “C”, “D”, “E”, “F”, “G”, “H”, “I”, “J”}.
Note: specific topics of interest have been redacted to avoid bias.
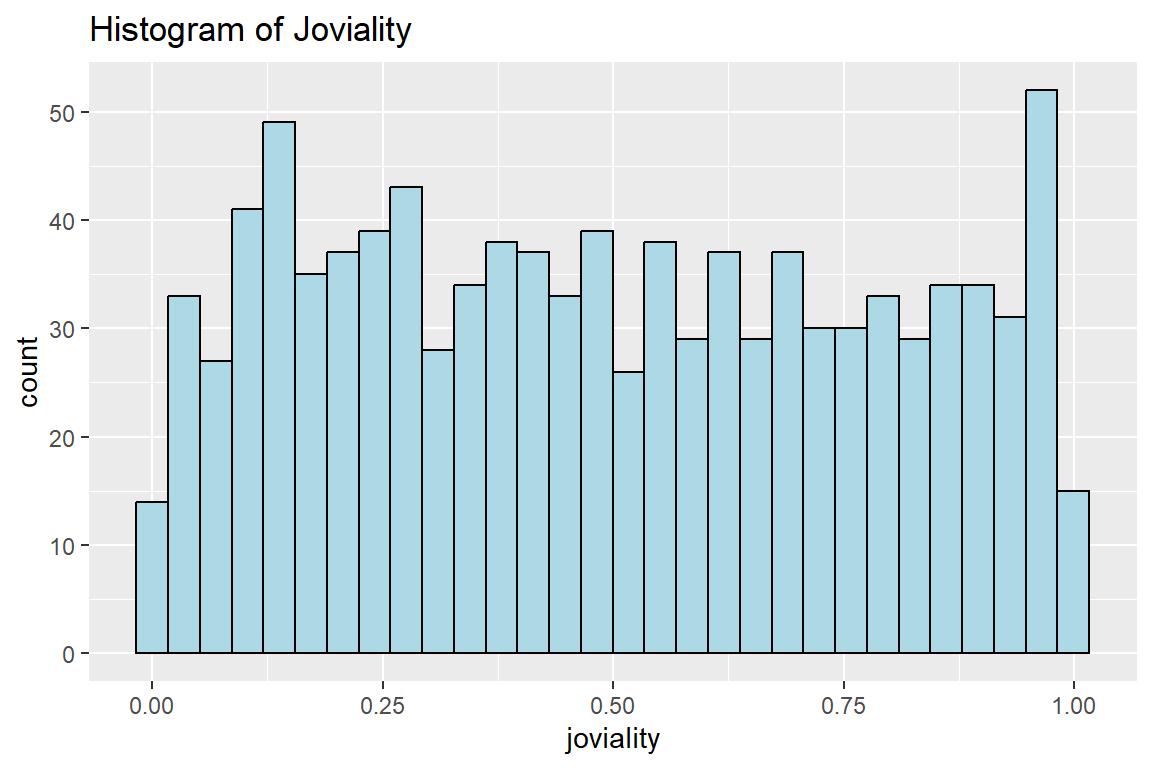
joviality
float
a value ranging from [0,1] indicating the participant’s overall happiness level at the start of the study.
Dataset 2 - FinancialJournal.csv
Contains information about financial transactions.
FinancialJournal.csv Dataset
Column Name
Data Type
Description
participantId
integer
unique ID corresponding to the participant affected
timestamp
datetime
the time when the check-in was logged
category
string factor
a string describing the expense category, one of {“Education”, “Food”, “Recreation”, “RentAdjustment”, “Shelter”, “Wage”}
amount
double
the amount of the transaction
4. Data Preparation
4.1 Install and launch R packages
The following packages will be used for this assignment.
package 'ggiraph' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\User\AppData\Local\Temp\RtmpMXtkEF\downloaded_packages
package 'gifski' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\User\AppData\Local\Temp\RtmpMXtkEF\downloaded_packages
package 'gapminder' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\User\AppData\Local\Temp\RtmpMXtkEF\downloaded_packages
package 'gganimate' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\User\AppData\Local\Temp\RtmpMXtkEF\downloaded_packages
package 'distributional' successfully unpacked and MD5 sums checked
package 'ggdist' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\User\AppData\Local\Temp\RtmpMXtkEF\downloaded_packages
package 'ggridges' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\User\AppData\Local\Temp\RtmpMXtkEF\downloaded_packages
4.3.2 Participant Expenditures by Month & Year for Each Category
To show the total finances by participant, we will first extract the Year and Month using the “extract” function. Next we will use “pivot_longer” consolidate all the expenditures to “spending” and use “pivot_wider” to extract the expenditure for each category.
We will also add a sum of total monthly spent as a new column.
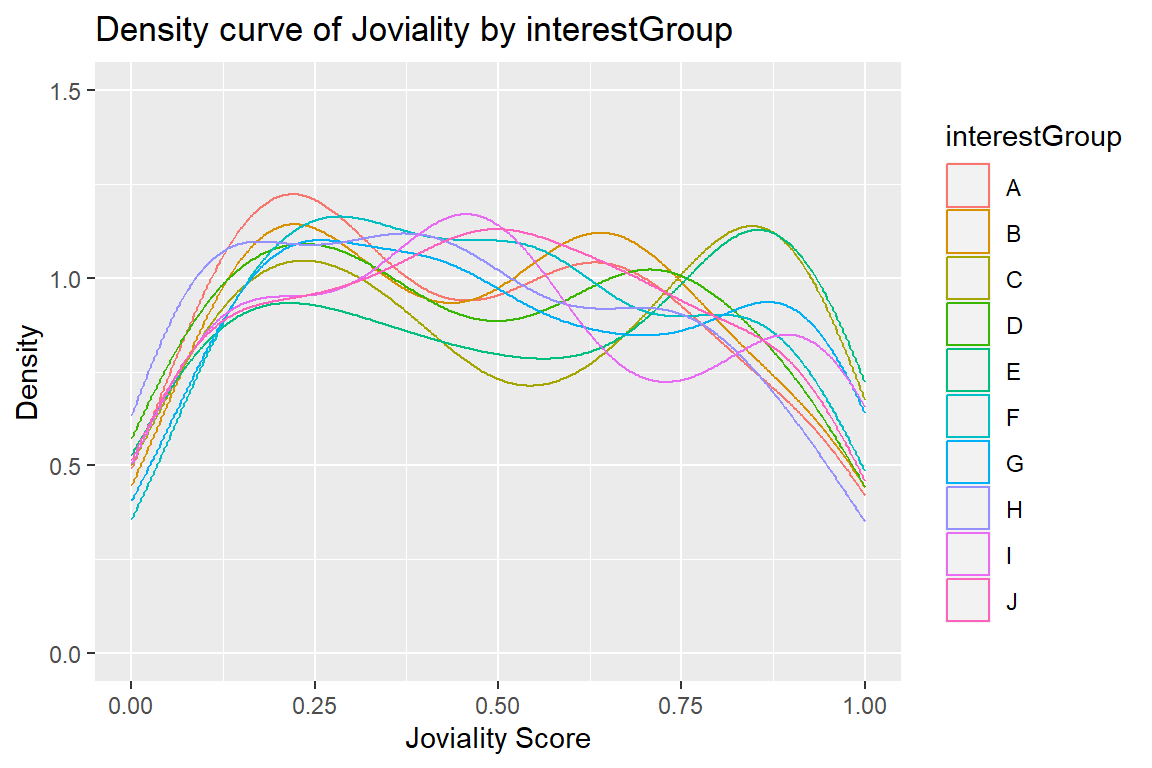
4.3.3 Participant Joviality by InterestGroups and haveKids
To deep dive in to possible analysis for demographic details for interest groups and those with/without kids, we will be deriving the count, mean, and standard deviation for these categories.